

Vi er på vej mod en ny revolution inden for webapplikationer, men først lidt historie for at sætte det i perspektiv …
I midthalvfemserne blev webapplikationer udviklet med simple scriptsprog såsom ASP og Perl, som blev afviklet på serveren og renderede nogle HTML-sider. Sidenhen kom andre til, såsom PHP og ASP.NET WebForms, hvor princippet er det samme, bortset fra nogle detaljer om hvordan det fungerer på serveren.
Første revolution – Gmail
Spol frem til 2004 hvor Google lancerede Gmail. Man havde opfundet teknologien til asynkrone kald mange år tidligere, men havde ikke før set et globalt, populært produkt som var baseret på “Ajax”-kald, som det hed dengang. Med asynkrone kald til webserveren kunne man opdatere en del af indholdet, hvilket alle med det samme kunne se gjorde en kæmpe forskel for brugeroplevelsen.
Det hedder måske stadig Ajax, men det er i dag nærmest implicit at det anvendes i webapplikationer, så i stedet er man begyndt at beskrive hvordan man bruger det. Mange moderne webapplikationer omtales som Single Page Application (SPA), hvilket i princippet er det samme som Gmail, men med SPA er det implicit at der anvendes et frontend-framework, såsom Angular, som gør det nemt at strukturere en SPA på en god måde.

Hvis man ikke tænker nærmere over det, har man måske en fornemmelse af at der har været en rivende udvikling inden for webapplikationer siden 90’erne. Reélt har der dog kun været en enkelt revolution i 2004 og alt andet er detaljer hvor man har gjort de samme ting lidt nemmere.
Den næste revolution
For at nå til at kunne udvikle en SPA, har man været nødt til at opfinde en masse teknologier som gør frontend-udvikling nemmere og bedre. Et eksempel er TypeScript som sikrer typestærk udvikling i browseren, i modsætning til den anarkistiske verden som Javascript normalt lever i. Man har også udviklet nogle best practices for hvordan man strukturerer sin kode, hvilket man igen har været nødt til, da der er kommet mere og mere af den.
Min påstand er, at man har gjort dette fordi man har haft behov for det, for at kunne lave bedre og bedre SPA’er.
Den afledte effekt er imidlertid at man kan lave store stabile applikationer med forretningslogik i browseren som fungerer godt, vedligeholdes effektivt og testes automatisk.
Ja, jeg skrev “forretningslogik i browseren”. I nogens ører lyder det måske som et oxymoron, men det er en klar tendens og jeg tror det vil være den næste revolution inden for udvikling af webapplikationer.
Det er allerede begyndt
SharePoint Framework er Microsofts nyeste tiltag inden for udvikling til SharePoint. Hvor man tidligere kunne inkludere serverside-kode, enten hostet i sin SharePoint -installation eller et andet sted, er fremgangsmåden med SharePoint Framework nu, at al kode, herunder forretningslogik, kører i javascript i browseren. Serveren håndterer stadig bl.a. datalag og rettighedsstyring, men på en standardiseret måde.
Det samme er tankegangen bag Happy Hyper, hvor rettighedsstyring og datastruktur konfigureres og afvikles på en standardiseret måde på platformen og giver mulighed for at lave rige webapplikationer i javascript og med frontend-frameworks. I modsætning til SharePoint er der ikke noget særligt framework som man skal bruge for at udvikle med Happy Hyper, da API’et er så simpelt og intuitivt at der ikke er behov for det.
Er forretningslogik hemmelig?
En af de ting som holder folk tilbage fra et afvikle forretningslogik i browseren er at man er i tvivl om hvorvidt forretningslogikken er hemmelig og om man kan risikere at brugeren ændrer på forretningslogikken, hvad der reélt er muligt så længe den afvikles i browseren. Det er en gyldig bekymring, men det eksponerer en dårlig separering af ansvar, hvis forretningslogikken også står for rettighedsstyring. Så det er ikke et problem med at placere forretningslogik i browseren, men nærmere et problem med opbygningen af den webapplikation man har udviklet. I langt de fleste tilfælde er forretningslogikken ikke hemmelig, tværtimod kæmper mange produktvirksomheder med at få dokumenteret deres forretningslogik så kunderne kan opnå bedre kendskab til den.
Der kan være enkelte undtagelser, men jeg kan vitterligt ikke komme på nogen og jeg vil gerne høre eksempler fra læsere, hvis I kan komme på situationer hvor forretningslogik er hemmelig.
Et problem som nogen måske vil spekulere over er, at hvis man har forretningslogikken i browseren, så er den nemmere at stjæle for konkurrenterne. Det er for så vidt korrekt, men det er meget sjældent det er en forretningslogik som udgår værdien af et stykke software. I stedet er det andre ting, såsom kunderne, tankegangen og holdet bag. Spørgsmålet er hvad forskellen er på at kunne se forretningslogikken udspille sig og i dokumentationen, sat i forhold til også at have adgang til noget javascript-kode. Forskellen er ikke stor. Som udvikler af webapplikationer må man leve med at man let kan få konkurrenter og den situation ændrer sig ikke betydeligt af, at forretningslogikken er eksponeret på klienten.
Er data hemmelig?
Som udgangspunkt anvendes data som brugeren har ret til i forretningslogikken, men her kan der være undtagelser. Det kan være en bruger skal have ret til at vide at 85% af medarbejderne er tilfredse, uden at have adgang til at vide hvilke medarbejdere der er tilfredse og hvilke der ikke er. Her er et eksempel hvor forretningslogikken ikke er hemmelig, men de data som skal indgå i forretningslogikken er hemmelig. Dette scenarie er relativt sjældent, men ikke usædvanligt. Scenariet optræder formentlig i de fleste webapplikationer i en eller anden grad.
Med SharePoint Framework kan man ikke imødekomme dette behov, men skal i stedet udvikle et add-in. Med Happy Hyper kan man markere, at en del af sin forretningslogik skal afvikles på serveren i stedet for på klienten, hvilket umiddelbart løser problemet. Det globale samfund af udviklere har dog ikke lagt sig fast på en bestemt måde at håndtere dette behov, andet end de er enige om der er brug for “elevation of privilege” af rettigheder. Det vil sige, det er et kendt behov at brugeren fra tid til anden har brug for at tilgå data som de egentligt ikke burde have adgang til, for at afvikle særlig forretningslogik.
Der er mange løsninger på denne udfordring og det er stadig uklart hvilken fremgangsmåde der bliver etableret som standard blandt udviklere. Jeg vil dog hævde, at det i en eller anden grad kommer til at handle om at afvikle kode på serveren, men der er to overordnede fremgangsmåder og det vil vise sig de næste par år hvilken der vil blive udviklernes favorit.
1. Afvikling af kode på serveren
Den ene løsning, som Happy Hyper pt. gør brug af er, at markere kode som skal afvikles på serveren i stedet for på klienten. Det gør at der stadig kun er ét sted hvor udviklingen foregår så det giver en god samlet oplevelse for udvikleren. Omvendt betyder det at klientkode er blandet med serverkode og det vil være optimalt hvis man kan sikre at det fungerer på præcis sammen måde, men det er ikke muligt at opnå det fuldstændig. F.eks. kan man opdatere elementer i sin UI fra sin forretningslogik i javascript – og det kan man mene om hvad man vil – men det vil være sværere at gøre når koden afvikles på serveren. Med teknologier som SignalR er det muligt at komme tæt på, men det bliver aldrig helt det samme.
Så det er en god løsning, den fungerer, er relativt nem at arbejde med, men den har også nogle tydelige ulemper som der ikke umiddelbart finden nogen løsning på.
2. Forudberegning af felter
I stedet for at give midlertidig adgang til data som brugeren ikke skal kunne tilgå, kan man i stedet have jobs der forudberegner data og anvender data som brugeren ikke har adgang til, for at lægge resultatet af beregningerne i felter som brugeren HAR adgang til. Dette har den altoverskyggende fordel at der ikke er brug for “elevation of privileges” med de kompleksiteter der kommer af dette. Desuden giver det en helt ren frontend uden man skal forholde sig til at en del af koden skal afvikles på serveren. Al kode kan afvikles på klienten og det giver også en hurtigere indlæringskurve for udviklere.
Udfordringen bliver derimod at der skal afvikles kompleks jobs på serveren, hvadenten de kører med regelmæssige mellemrum eller bliver aktiveret når data ændres, vil udfordringen være hvilken kode det er som afvikles og hvordan den vedligeholdes, debugges osv. Der vil jo være tale om helt traditionel serverside-kode og hvad har vi så vundet ved at flytte næsten al forretningslogik tilbage i browseren, hvis det stadig skal spille sammen med komplekse serverside-applikationer som er skrevet i et andet sprog og måske kræver en anden infrastruktur.
Beregnede felter er et velkendt mønster, som har eksisteret siden de første databaser, men udfordringen er nu at finde et sprog eller en fremgangsmåde for dette som er adskilt fra den konkrete datakilde eller teknologi som anvendes. En oplagt mulighed er serverless functions, som blandt andet AWS og Azure satser på er fremtiden inden for skalerbare applikationer. De kan skrives i javascript.
Udfordringen er det kræver infrastruktur og konfiguration og i sin nuværende form egner det sig til udviklerne af en platform og kun sekundært udviklere på en platform. Det er med andre ord et større setup som gør at udviklerne skal bruge tid på andet end at implementere den forretningslogik som skaber værdi for dem. Derfor er denne fremgangsmåde endnu ikke helt et oplagt valg, men det ser ud til at det er denne vej pilen peger.
Hvad med performance?
Forretningslogik i browseren betyder flere kald til serveren og hvis man lægger dem sammen og tæller tiden op, vil man formentlig kunne observere at resultatet tager længere tid for at blive tilgængeligt end det ville hvis man havde en traditionel applikation med forretningslogik på serveren.
Men beregningen er ikke så simpel. Med forretningslogik i browseren, vil siden blive åbnet hurtigere og de første resultater vil blive tilgængelige tidligere – eller sådan har man i hvert fald mulighed for at udvikle sin applikation.
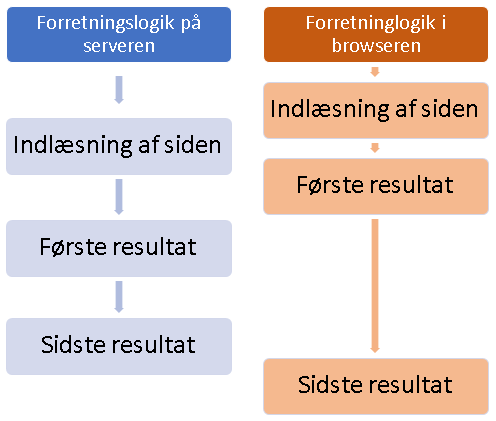
Det er helt klart et holdningsspørgsmål, men jeg mener det giver den bedste brugeroplevelse at få det første resultat hurtigt og så er det mindre vigtigt om det sidste resultat kommer efter 2 eller 2½ sekund.
Det er desuden en fordel for stabiliteten af webapplikationen hvis der er flere små og simple kald i modsætning til nogle større komplekse kald, som potentielt kan blokere server og datalag (afhængigt af infrastruktur og arkitektur).
Det vil være forkert at sige, at det er bedre for performance at have forretningslogik i browseren, men pointen er at performance behøver ikke blive et problem med denne opbygning. Man skal som udvikler og UX’er ind i en vane med at tænke over hvilke resultater man kan vise først og så kan man give en god brugeroplevelse. Det er den gode brugeroplevelse det handler om, ikke performancemålinger.
Hvornår sker det?
Det er som sagt allerede begyndt. Det vil ske som når man laver popcorn. De første er allerede begyndt at poppe. Snart popper de næsten allesammen. Til sidst ligger der nogle brændte kerner i bunden som bare ikke ville poppe. Dem smider vi ud.